landmarks-regression-retail-0009¶
Use Case and High-Level Description¶
This is a lightweight landmarks regressor for the Smart Classroom scenario. It has a classic convolutional design: stacked 3x3 convolutions, batch normalizations, PReLU activations, and poolings. Final regression is done by the global depthwise pooling head and FullyConnected layers. The model predicts five facial landmarks: two eyes, nose, and two lip corners.
Example¶

Specification¶
Metric |
Value |
|---|---|
Mean Normed Error (on VGGFace2) |
0.0705 |
Face location requirements |
Tight crop |
GFlops |
0.021 |
MParams |
0.191 |
Source framework |
PyTorch* |
Normed Error (NE) for ith sample has the following form:
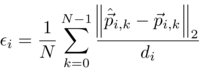
where N is the number of landmarks, p-hat and p are, correspondingly, the prediction and ground truth vectors of kth landmark of ith sample, and di is the interocular distance for ith sample.
Inputs¶
Image, name: 0, shape: 1, 3, 48, 48 in the format B, C, H, W, where:
B- batch sizeC- number of channelsH- image heightW- image width
The expected color order is BGR.
Outputs¶
The net outputs a blob with the shape: 1, 10, 1, 1, containing a row-vector of 10 floating point values
for five landmarks coordinates in the form (x0, y0, x1, y1, …, x4, y4).
All the coordinates are normalized to be in range [0, 1].
Demo usage¶
The model can be used in the following demos provided by the Open Model Zoo to show its capabilities:
Legal Information¶
[*] Other names and brands may be claimed as the property of others.