Cutting Off Parts of a Model¶
Sometimes some parts of a model must be removed while the Model Optimizer is converting models to the Intermediate Representation. This chapter describes methods of doing cutting off parts of a model using Model Optimizer command-line options. Model cutting applies mostly to TensorFlow* models, but is also useful for other frameworks. In this chapter, TensorFlow examples are used for illustration.
Purpose of Model Cutting¶
The following examples are the situations when model cutting is useful or even required:
model has pre- or post-processing parts that cannot be translated to existing OpenVINO operations.
model has a training part that is convenient to be kept in the model, but not used during inference.
model is too complex (contains lots of unsupported operations that cannot be easily implemented as custom layers), so the complete model cannot be converted in one shot.
problem with model conversion in the Model Optimizer or inference in the OpenVINO Runtime occurred. To localize the issue, limit the scope for conversion by iteratively searching for problematic places in the model.
single custom layer or a combination of custom layers is isolated for debugging purposes.
Command-Line Options¶
Model Optimizer provides command line options --input and --output to specify new entry and exit nodes, while ignoring the rest of the model:
--inputoption accepts a comma-separated list of layer names of the input model that should be treated as new entry points to the model.--outputoption accepts a comma-separated list of layer names of the input model that should be treated as new exit points from the model.
The --input option is required for cases unrelated to model cutting. For example, when the model contains several inputs and --input_shape or --mean_values options are used, you should use the --input option to specify the order of input nodes for correct mapping between multiple items provided in --input_shape and --mean_values and the inputs in the model. Details on these options are out of scope for this document, which focuses on model cutting.
Model cutting is illustrated with Inception V1. This model is in models/research/slim repository. This section describes pre-work to prepare the model for the Model Optimizer to be ready to proceed with this chapter.
Default Behavior without input and output¶
The input model is converted as a whole if neither --input nor --output command line options are used. All Placeholder operations in a TensorFlow* graph are automatically identified as entry points. The Input layer type is generated for each of them. All nodes that have no consumers are automatically identified as exit points.
For Inception_V1, there is one Placeholder : input. If the model is viewed in the TensorBoard*, the input operation is easy to find:
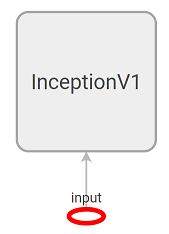
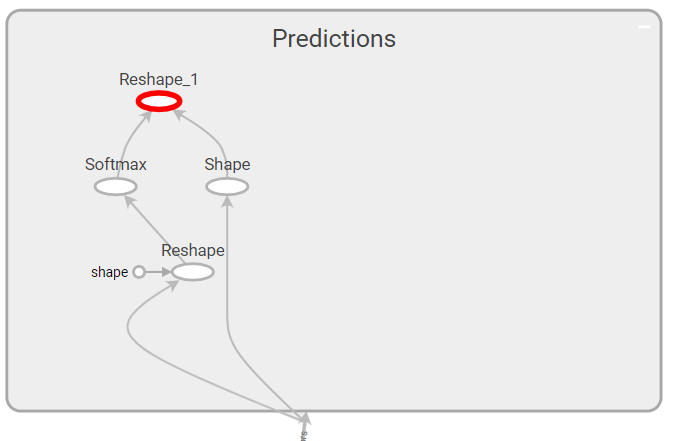
There is only one output operation, which enclosed in a nested name scope InceptionV1/Logits/Predictions, the Reshape operation has a full name InceptionV1/Logits/Predictions/Reshape_1.
In the TensorBoard, it looks the following way together with some predecessors:
Convert this model and put the results in a writable output directory:
mo --input_model inception_v1.pb -b 1 --output_dir <OUTPUT_MODEL_DIR>(The other examples on this page assume that you first cd to the model_optimizer directory and add the --output_dir argument with a directory where you have write permissions.)
The output .xml file with an Intermediate Representation contains the Input layer among other layers in the model:
<layer id="286" name="input" precision="FP32" type="Input">
<output>
<port id="0">
<dim>1</dim>
<dim>3</dim>
<dim>224</dim>
<dim>224</dim>
</port>
</output>
</layer>The input layer is converted from the TensorFlow graph Placeholder operation input and has the same name.
The -b option is used here for conversion to override a possible undefined batch size (coded as -1 in TensorFlow models). If a model was frozen with a defined batch size, you may omit this option in all the examples.
The last layer in the model is InceptionV1/Logits/Predictions/Reshape_1, which matches an output operation in the TensorFlow graph:
<layer id="389" name="InceptionV1/Logits/Predictions/Reshape_1" precision="FP32" type="Reshape">
<data axis="0" dim="1,1001" num_axes="-1"/>
<input>
<port id="0">
<dim>1</dim>
<dim>1001</dim>
</port>
</input>
<output>
<port id="1">
<dim>1</dim>
<dim>1001</dim>
</port>
</output>
</layer>Due to automatic identification of inputs and outputs, you do not need to provide the --input and --output options to convert the whole model. The following commands are equivalent for the Inception V1 model:
mo --input_model inception_v1.pb -b 1 --output_dir <OUTPUT_MODEL_DIR>
mo --input_model inception_v1.pb -b 1 --input input --output InceptionV1/Logits/Predictions/Reshape_1 --output_dir <OUTPUT_MODEL_DIR>The Intermediate Representations are identical for both conversions. The same is true if the model has multiple inputs and/or outputs.
Model Cutting¶
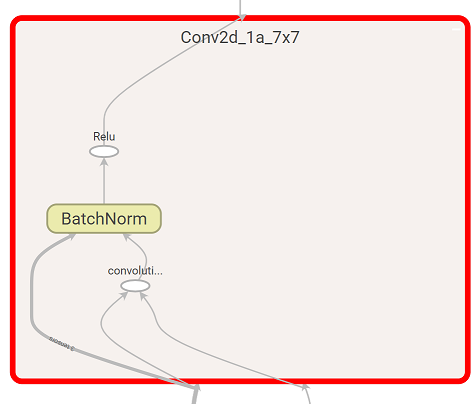
Now consider how to cut some parts of the model off. This chapter uses the first convolution block InceptionV1/InceptionV1/Conv2d_1a_7x7 of the Inception V1 model to illustrate cutting:
Cutting at the End¶
If you want to cut your model at the end, you have the following options:
The following command cuts off the rest of the model after the
InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu, making this node the last in the model:mo --input_model inception_v1.pb -b 1 --output=InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output_dir <OUTPUT_MODEL_DIR>
The resulting Intermediate Representation has three layers:
<?xml version="1.0" ?> <net batch="1" name="model" version="2"> <layers> <layer id="3" name="input" precision="FP32" type="Input"> <output> <port id="0">...</port> </output> </layer> <layer id="5" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/convolution" precision="FP32" type="Convolution"> <data dilation-x="1" dilation-y="1" group="1" kernel-x="7" kernel-y="7" output="64" pad-x="2" pad-y="2" stride="1,1,2,2" stride-x="2" stride-y="2"/> <input> <port id="0">...</port> </input> <output> <port id="3">...</port> </output> <blobs> <weights offset="0" size="37632"/> <biases offset="37632" size="256"/> </blobs> </layer> <layer id="6" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu" precision="FP32" type="ReLU"> <input> <port id="0">...</port> </input> <output> <port id="1">...</port> </output> </layer> </layers> <edges> <edge from-layer="3" from-port="0" to-layer="5" to-port="0"/> <edge from-layer="5" from-port="3" to-layer="6" to-port="0"/> </edges> </net>
As you can see in the TensorBoard picture, the original model has more nodes than Intermediate Representation. Model Optimizer has fused batch normalization
InceptionV1/InceptionV1/Conv2d_1a_7x7/BatchNormto the convolutionInceptionV1/InceptionV1/Conv2d_1a_7x7/convolution, and it is not present in the final Intermediate Representation. This is not an effect of the--outputoption, it is usual behavior of the Model Optimizer for batch normalizations and convolutions. The effect of the--outputis that theReLUlayer becomes the last one in the converted model.The following command cuts the edge that comes from 0 output port of the
InceptionV1/InceptionV1/Conv2d_1a_7x7/Reluand the rest of the model, making this node the last one in the model:mo --input_model inception_v1.pb -b 1 --output InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu:0 --output_dir <OUTPUT_MODEL_DIR>
The resulting Intermediate Representation has three layers, which are the same as in the previous case:
<?xml version="1.0" ?> <net batch="1" name="model" version="2"> <layers> <layer id="3" name="input" precision="FP32" type="Input"> <output> <port id="0">...</port> </output> </layer> <layer id="5" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/convolution" precision="FP32" type="Convolution"> <data dilation-x="1" dilation-y="1" group="1" kernel-x="7" kernel-y="7" output="64" pad-x="2" pad-y="2" stride="1,1,2,2" stride-x="2" stride-y="2"/> <input> <port id="0">...</port> </input> <output> <port id="3">...</port> </output> <blobs> <weights offset="0" size="37632"/> <biases offset="37632" size="256"/> </blobs> </layer> <layer id="6" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu" precision="FP32" type="ReLU"> <input> <port id="0">...</port> </input> <output> <port id="1">...</port> </output> </layer> </layers> <edges> <edge from-layer="3" from-port="0" to-layer="5" to-port="0"/> <edge from-layer="5" from-port="3" to-layer="6" to-port="0"/> </edges> </net>
This type of cutting is useful to cut edges in case of multiple output edges.
The following command cuts the edge that comes to 0 input port of the
InceptionV1/InceptionV1/Conv2d_1a_7x7/Reluand the rest of the model includingInceptionV1/InceptionV1/Conv2d_1a_7x7/Relu, deleting this node and making the previous nodeInceptionV1/InceptionV1/Conv2d_1a_7x7/Conv2Dthe last in the model:mo --input_model inception_v1.pb -b 1 --output=0:InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output_dir <OUTPUT_MODEL_DIR>
The resulting Intermediate Representation has two layers, which are the same as the first two layers in the previous case:
<?xml version="1.0" ?> <net batch="1" name="inception_v1" version="2"> <layers> <layer id="0" name="input" precision="FP32" type="Input"> <output> <port id="0">...</port> </output> </layer> <layer id="1" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Conv2D" precision="FP32" type="Convolution"> <data auto_pad="same_upper" dilation-x="1" dilation-y="1" group="1" kernel-x="7" kernel-y="7" output="64" pad-b="3" pad-r="3" pad-x="2" pad-y="2" stride="1,1,2,2" stride-x="2" stride-y="2"/> <input> <port id="0">...</port> </input> <output> <port id="3">...</port> </output> <blobs> <weights offset="0" size="37632"/> <biases offset="37632" size="256"/> </blobs> </layer> </layers> <edges> <edge from-layer="0" from-port="0" to-layer="1" to-port="0"/> </edges> </net>
Cutting from the Beginning¶
If you want to go further and cut the beginning of the model, leaving only the ReLU layer, you have the following options:
You can use the following command line, where
--inputand--outputspecify the same node in the graph:mo --input_model=inception_v1.pb -b 1 --output InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --input InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output_dir <OUTPUT_MODEL_DIR>
The resulting Intermediate Representation looks as follows:
<xml version="1.0"> <net batch="1" name="model" version="2"> <layers> <layer id="0" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu/placeholder_port_0" precision="FP32" type="Input"> <output> <port id="0">...</port> </output> </layer> <layer id="2" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu" precision="FP32" type="ReLU"> <input> <port id="0">...</port> </input> <output> <port id="1">...</port> </output> </layer> </layers> <edges> <edge from-layer="0" from-port="0" to-layer="2" to-port="0"/> </edges> </net>
Inputlayer is automatically created to feed the layer that is converted from the node specified in--input, which isInceptionV1/InceptionV1/Conv2d_1a_7x7/Reluin this case. Model Optimizer does not replace theReLUnode by theInputlayer, it produces such Intermediate Representation to make the node be the first executable node in the final Intermediate Representation. So the Model Optimizer creates enoughInputsto feed all input ports of the node that is passed in--input.Even though
--input_shapeis not specified in the command line, the shapes for layers are inferred from the beginning of the original TensorFlow* model to the point at which the new input is defined. It has the same shape [1,64,112,112] as the model converted as a whole or without cutting off the beginning.You can cut edge incoming to layer by port number. To specify incoming port use notation
--input=port:input_node. So, to cut everything beforeReLUlayer, cut edge incoming in port 0 ofInceptionV1/InceptionV1/Conv2d_1a_7x7/Relunode:mo --input_model inception_v1.pb -b 1 --input 0:InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output_dir <OUTPUT_MODEL_DIR>
The resulting Intermediate Representation looks as follows:
<xml version="1.0"> <net batch="1" name="model" version="2"> <layers> <layer id="0" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu/placeholder_port_0" precision="FP32" type="Input"> <output> <port id="0">...</port> </output> </layer> <layer id="2" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu" precision="FP32" type="ReLU"> <input> <port id="0">...</port> </input> <output> <port id="1">...</port> </output> </layer> </layers> <edges> <edge from-layer="0" from-port="0" to-layer="2" to-port="0"/> </edges> </net>
Inputlayer is automatically created to feed the layer that is converted from the node specified in--input, which isInceptionV1/InceptionV1/Conv2d_1a_7x7/Reluin this case. Model Optimizer does not replace theReLUnode by theInputlayer, it produces such Intermediate Representation to make the node be the first executable node in the final Intermediate Representation. So the Model Optimizer creates enoughInputsto feed all input ports of the node that is passed in--input.Even though
--input_shapeis not specified in the command line, the shapes for layers are inferred from the beginning of the original TensorFlow* model to the point at which the new input is defined. It has the same shape [1,64,112,112] as the model converted as a whole or without cutting off the beginning.You can cut edge outcoming from layer by port number. To specify outcoming port use notation
--input=input_node:port. So, to cut everything beforeReLUlayer, cut edge fromInceptionV1/InceptionV1/Conv2d_1a_7x7/BatchNorm/batchnorm/add_1node toReLU:mo --input_model inception_v1.pb -b 1 --input InceptionV1/InceptionV1/Conv2d_1a_7x7/BatchNorm/batchnorm/add_1:0 --output InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output_dir <OUTPUT_MODEL_DIR>
The resulting Intermediate Representation looks as follows:
<xml version="1.0"> <net batch="1" name="model" version="2"> <layers> <layer id="0" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/BatchNorm/batchnorm/add_1/placeholder_out_port_0" precision="FP32" type="Input"> <output> <port id="0">...</port> </output> </layer> <layer id="1" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu" precision="FP32" type="ReLU"> <input> <port id="0">...</port> </input> <output> <port id="1">...</port> </output> </layer> </layers> <edges> <edge from-layer="0" from-port="0" to-layer="1" to-port="0"/> </edges> </net>
Shape Override for New Inputs¶
The input shape can be overridden with --input_shape. In this case, the shape is applied to the node referenced in --input, not to the original Placeholder in the model. For example, the command below
mo --input_model inception_v1.pb --input_shape=[1,5,10,20] --output InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --input InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output_dir <OUTPUT_MODEL_DIR>gives the following shapes in the Input and ReLU layers:
<layer id="0" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu/placeholder_port_0" precision="FP32" type="Input">
<output>
<port id="0">
<dim>1</dim>
<dim>20</dim>
<dim>5</dim>
<dim>10</dim>
</port>
</output>
</layer>
<layer id="3" name="InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu" precision="FP32" type="ReLU">
<input>
<port id="0">
<dim>1</dim>
<dim>20</dim>
<dim>5</dim>
<dim>10</dim>
</port>
</input>
<output>
<port id="1">
<dim>1</dim>
<dim>20</dim>
<dim>5</dim>
<dim>10</dim>
</port>
</output>
</layer>An input shape [1,20,5,10] in the final Intermediate Representation differs from the shape [1,5,10,20] specified in the command line, because the original TensorFlow* model uses NHWC layout, but the Intermediate Representation uses NCHW layout. So usual NHWC to NCHW layout conversion occurred.
When --input_shape is specified, shape inference inside the Model Optimizer is not performed for the nodes in the beginning of the model that are not included in the translated region. It differs from the case when --input_shape is not specified as noted in the previous section where the shape inference is still performed for such nodes to deduce shape for the layers that should fall into the final Intermediate Representation. So --input_shape should be used for a model with a complex graph with loops, which are not supported by the Model Optimizer, to exclude such parts from the Model Optimizer shape inference process completely.
Inputs with Multiple Input Ports¶
There are operations that contain more than one input ports. In the example considered here, the convolution InceptionV1/InceptionV1/Conv2d_1a_7x7/convolution is such operation. When --input_shape is not provided, a new Input layer is created for each dynamic input port for the node. If a port is evaluated to a constant blob, this constant remains in the model and a corresponding input layer is not created. TensorFlow convolution used in this model contains two ports:
port 0: input tensor for convolution (dynamic)
port 1: convolution weights (constant)
Following this behavior, the Model Optimizer creates an Input layer for port 0 only, leaving port 1 as a constant. So the result of:
mo --input_model inception_v1.pb -b 1 --input InceptionV1/InceptionV1/Conv2d_1a_7x7/convolution --output_dir <OUTPUT_MODEL_DIR>is identical to the result of conversion of the model as a whole, because this convolution is the first executable operation in Inception V1.
Different behavior occurs when --input_shape is also used as an attempt to override the input shape:
mo --input_model inception_v1.pb--input=InceptionV1/InceptionV1/Conv2d_1a_7x7/convolution --input_shape [1,224,224,3] --output_dir <OUTPUT_MODEL_DIR>An error occurs (for more information, see FAQ #30):
[ ERROR ] Node InceptionV1/InceptionV1/Conv2d_1a_7x7/convolution has more than 1 input and input shapes were provided.
Try not to provide input shapes or specify input port with PORT:NODE notation, where PORT is an integer.
For more information, see FAQ #30In this case, when --input_shape is specified and the node contains multiple input ports, you need to specify an input port index together with an input node name. The input port index is specified in front of the node name with ‘:’ as a separator (PORT:NODE). In the considered case, the port index 0 of the node InceptionV1/InceptionV1/Conv2d_1a_7x7/convolution should be specified as 0:InceptionV1/InceptionV1/Conv2d_1a_7x7/convolution.
The correct command line is:
mo --input_model inception_v1.pb --input 0:InceptionV1/InceptionV1/Conv2d_1a_7x7/convolution --input_shape=[1,224,224,3] --output_dir <OUTPUT_MODEL_DIR>