Using Encrypted Models with OpenVINO™¶
Deploying deep-learning capabilities to edge devices can present security challenges, for example, ensuring inference integrity or providing copyright protection of your deep-learning models.
One possible solution is to use cryptography to protect models as they are deployed and stored on edge devices. Model encryption, decryption and authentication are not provided by OpenVINO but can be implemented with third-party tools, like OpenSSL*. While implementing encryption, ensure that you use the latest versions of tools and follow cryptography best practices.
This guide demonstrates how to use OpenVINO securely with protected models.
Secure Model Deployment¶
After a model is optimized by the OpenVINO Model Optimizer, it’s deployed to target devices in the Intermediate Representation (IR) format. An optimized model is stored on an edge device and executed by the OpenVINO Runtime. (ONNX, PDPD models can also be read natively by the OpenVINO Runtime.)
To protect deep-learning models, you can encrypt an optimized model before deploying it to the edge device. The edge device should keep the stored model protected at all times and have the model decrypted in runtime only for use by the OpenVINO Runtime.
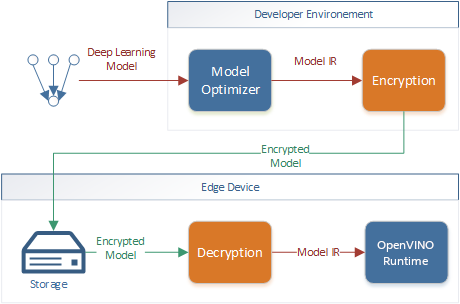
Loading Encrypted Models¶
The OpenVINO Runtime requires model decryption before loading. Allocate a temporary memory block for model decryption and use the ov::Core::read_model method to load the model from a memory buffer. For more information, see the ov::Core Class Reference Documentation.
std::vector<uint8_t> model_data, weights_data;
std::string password; // taken from an user
std::ifstream model_file("model.xml"), weights_file("model.bin");
// Read model files and decrypt them into temporary memory block
decrypt_file(model_file, password, model_data);
decrypt_file(weights_file, password, weights_data);Hardware-based protection such as Intel Software Guard Extensions (Intel SGX) can be utilized to protect decryption operation secrets and bind them to a device. For more information, go to Intel Software Guard Extensions.
Use ov::Core::read_model to set model representations and weights respectively.
Currently there is no way to read external weights from memory for ONNX models. The ov::Core::read_model(const std::string& model, const Tensor& weights) method should be called with weights passed as an empty ov::Tensor.
ov::Core core;
// Load model from temporary memory block
std::string str_model(model_data.begin(), model_data.end());
auto model = core.read_model(str_model,
ov::Tensor(ov::element::u8, {weights_data.size()}, weights_data.data()));Additional Resources¶
Intel® Distribution of OpenVINO™ toolkit home page: https://software.intel.com/en-us/openvino-toolkit
Model Optimizer Developer Guide: Model Optimizer Developer Guide
For more information on Sample Applications, see the OpenVINO Samples Overview
For information on a set of pre-trained models, see the Overview of OpenVINO™ Toolkit Pre-Trained Models
For IoT Libraries and Code Samples see the Intel® IoT Developer Kit.