Optimizing models post-training¶
Introduction¶
Post-training model optimization is the process of applying special methods without model retraining or fine-tuning, for example, post-training 8-bit quantization. Therefore, this process does not require a training dataset or a training pipeline in the source DL framework. To apply post-training methods in OpenVINO, you need:
A floating-point precision model, FP32 or FP16, converted into the OpenVINO Intermediate Representation (IR) format and run on CPU with the OpenVINO.
A representative calibration dataset representing a use case scenario, for example, 300 samples.
In case of accuracy constraints, a validation dataset and accuracy metrics should be available.
For the needs of post-training optimization, OpenVINO provides a Post-training Optimization Tool (POT) which supports the uniform integer quantization method. This method allows substantially increasing inference performance and reducing the model size.
Figure below shows the optimization workflow with POT:
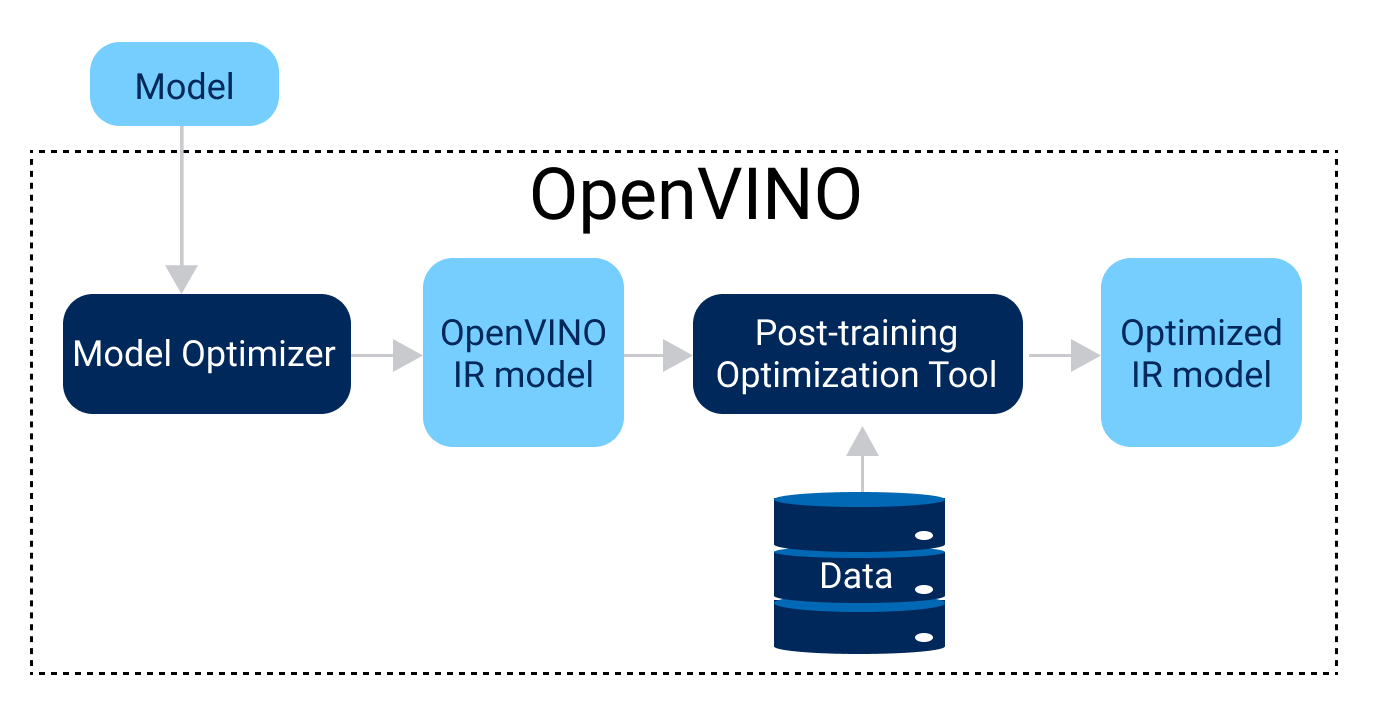
Quantizing models with POT¶
POT provides two main quantization methods that can be used depending on the user’s needs and requirements:
Default Quantization is a recommended method that provides fast and accurate results in most cases. It requires only a unannotated dataset for quantization. For details, see the Default Quantization algorithm documentation.
Accuracy-aware Quantization is an advanced method that allows keeping accuracy at a predefined range at the cost of performance improvement in case when
Default Quantizationcannot guarantee it. The method requires annotated representative dataset and may require more time for quantization. For details, see the Accuracy-aware Quantization algorithm documentation.
HW platforms support different integer precisions and quantization parameters, for example 8-bit in CPU, GPU, VPU, 16-bit for GNA. POT abstracts this complexity by introducing a concept of “target device” that is used to set quantization settings specific to the device. The target_device parameter is used for this purpose.
Note
There is a special target_device: "ANY" which leads to portable quantized models compatible with CPU, GPU, and VPU devices. GNA-quantized models are compatible only with CPU.
For benchmarking results collected for the models optimized with the POT tool, refer to INT8 vs FP32 Comparison on Select Networks and Platforms.