Further Low-Level Implementation Details¶
Throughput on the CPU: Internals¶
As explained in the throughput-related section, the OpenVINO streams is a mean of running multiple requests in parallel. In order to best serve multiple inference requests executed simultaneously, the inference threads are grouped/pinned to the particular CPU cores, constituting the “CPU” streams. This provides much better performance for the networks than batching especially for the many-core machines:
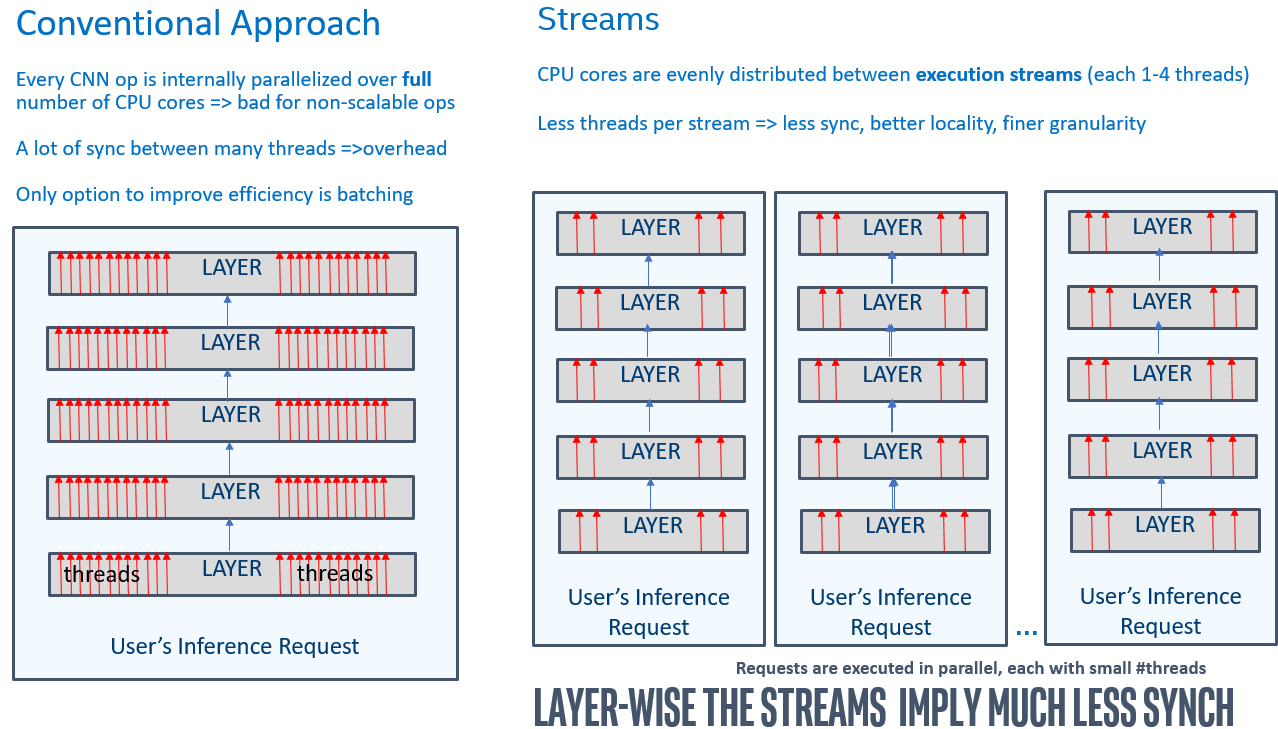
Compared with the batching, the parallelism is somewhat transposed (i.e. performed over inputs, with much less synchronization within CNN ops):
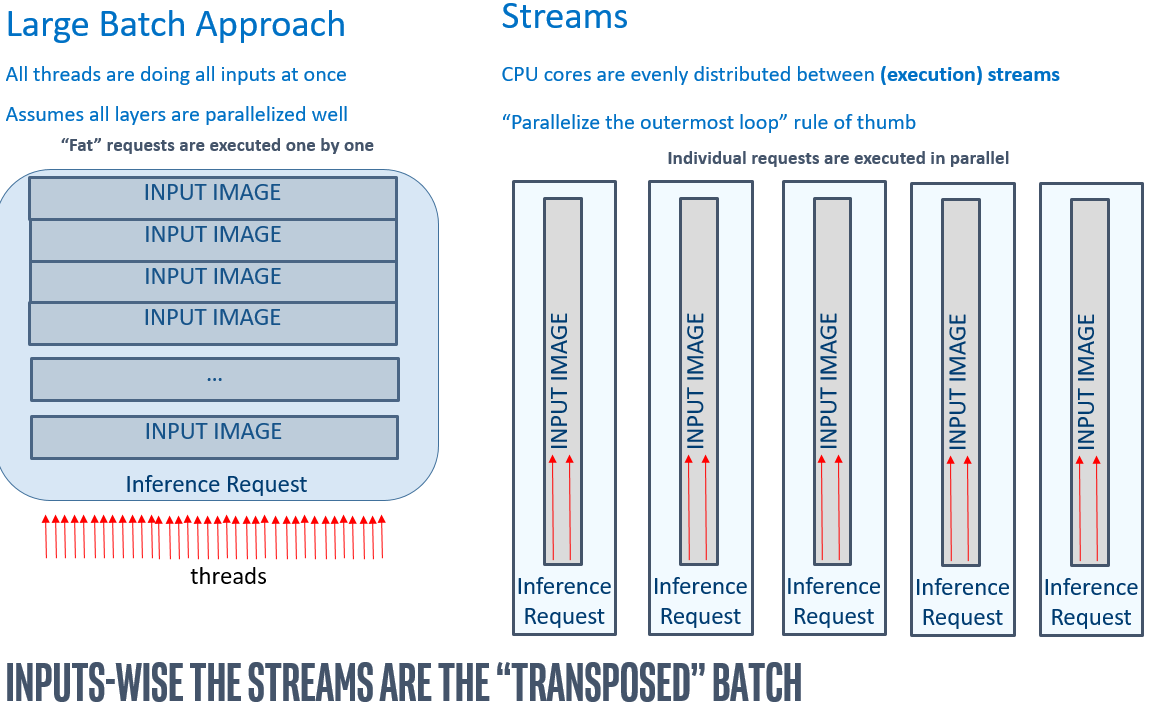
Note that high-level performance hints allows the implementation to select the optimal number of the streams, depending on the model compute demands and CPU capabilities (including int8 inference hardware acceleration, number of cores, etc).
Automatic Batching Internals¶
As explained in the section on the automatic batching, the feature performs on-the-fly grouping of the inference requests to improve device utilization. The Automatic Batching relaxes the requirement for an application to saturate devices like GPU by explicitly using a large batch. It performs transparent inputs gathering from individual inference requests followed by the actual batched execution, with no programming effort from the user:

Essentially, the Automatic Batching shifts the asynchronousity from the individual requests to the groups of requests that constitute the batches. Thus, for the execution to be efficient it is very important that the requests arrive timely, without causing a batching timeout. Normally, the timeout should never be hit. It is rather a graceful way to handle the application exit (when the inputs are not arriving anymore, so the full batch is not possible to collect).
So if your workload experiences the timeouts (resulting in the performance drop, as the timeout value adds itself to the latency of every request), consider balancing the timeout value vs the batch size. For example in many cases having smaller timeout value and batch size may yield better performance than large batch size, but coupled with the timeout value that cannot guarantee accommodating the full number of the required requests.
Finally, following the “get_tensor idiom” section from the general optimizations helps the Automatic Batching to save on inputs/outputs copies. Thus, in your application always prefer the “get” versions of the tensors’ data access APIs.