Introduction to OpenCV Graph API (G-API)¶
OpenCV Graph API (G-API) is an OpenCV module targeted to make regular image and video processing fast and portable. G-API is a special module in OpenCV – in contrast with the majority of other main modules, this one acts as a framework rather than some specific CV algorithm.
G-API is positioned as a next level optimization enabler for computer vision, focusing not on particular CV functions but on the whole algorithm optimization.
G-API provides means to define CV operations, construct graphs (in form of expressions) using it, and finally implement and run the operations for a particular backend.
The idea behind G-API is that if an algorithm can be expressed in a special embedded language (currently in C++), the framework can catch its sense and apply a number of optimizations to the whole thing automatically. Particular optimizations are selected based on which kernels and backends are involved in the graph compilation process, for example, the graph can be offloaded to GPU via the OpenCL backend, or optimized for memory consumption with the Fluid backend. Kernels, backends, and their settings are parameters to the graph compilation, so the graph itself does not depend on any platform-specific details and can be ported easily.
Note
Graph API (G-API) was introduced in the most recent major OpenCV 4.0 release and now is being actively developed. The API is volatile at the moment and there may be minor but compatibility-breaking changes in the future.
G-API Concepts¶
Graphs are built by applying operations to data objects.
API itself has no “graphs”, it is expression-based instead.
Data objects do not hold actual data, only capture dependencies.
Operations consume and produce data objects.
A graph is defined by specifying its boundaries with data objects:
What data objects are inputs to the graph?
What are its outputs?
The paragraphs below explain the G-API programming model and development workflow.
Programming Model¶
Building graphs is easy with G-API. In fact, there is no notion of graphs exposed in the API, so the user doesn’t need to operate in terms of “nodes” and “edges” — instead, graphs are constructed implicitly via expressions in a “functional” way. Expression-based graphs are built using two major concepts: operations and data objects.
In G-API, every graph begins and ends with data objects; data objects are passed to operations which produce (“return”) their results — new data objects, which are then passed to other operations, and so on. You can declare their own operations, G-API does not distinguish user-defined operations from its own predefined ones in any way.
After the graph is defined, it needs to be compiled for execution. During the compilation, G-API figures out what the graph looks like, which kernels are available to run the operations in the graph, how to manage heterogeneity and to optimize the execution path. The result of graph compilation is a so-called “compiled” object. This object encapsulates the execution sequence for the graph inside and operates on real image data. You can set up the compilation process using various compilation arguments. Backends expose some of their options as these arguments; also, actual kernels and DL network settings are passed into the framework this way.
G-API supports graph compilation for two execution modes, regular and streaming, producing different types of compiled objects as the result.
Regular compiled objects are represented with class GCompiled, which follows functor-like semantics and has an overloaded operator(). When called for execution on the given input data, the GCompiled functor blocks the current thread and processes the data immediately — like a regular C++ function. By default, G-API tries to optimize the execution time for latency in this compilation mode.
Starting with OpenCV 4.2, G-API can also produce GStreamingCompiled objects that better fit the asynchronous pipelined execution model. This compilation mode is called streaming mode, and G-API tries to optimize the overall throughput by implementing the pipelining technique as described above. We will use both in our example.
The overall process for the regular case is summarized in the diagram below:
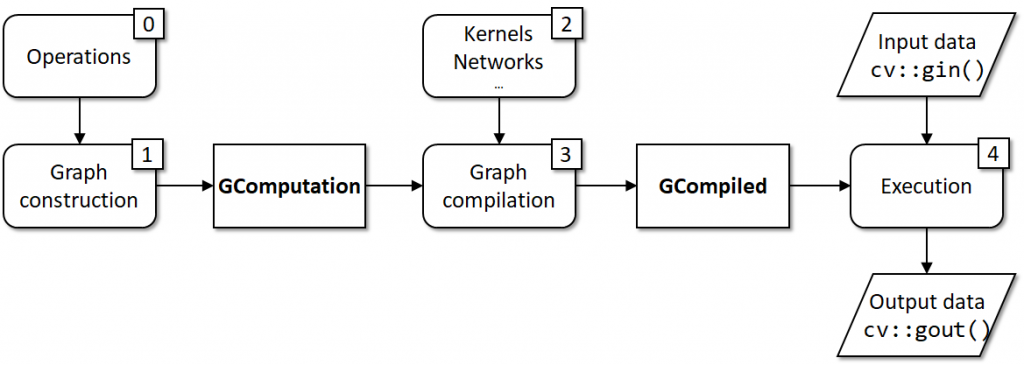
The graph is built with operations so having operations defined (0) is a basic prerequisite; a constructed expression graph (1) forms a cv::GComputation object; kernels (2) which implement operations are the basic requirement to the graph compilation (3); the actual execution (4) is handled by a cv::GCompiled object with takes input and produces output data.
Development Workflow¶
One of the ways to organize a G-API development workflow is presented in the diagram below:
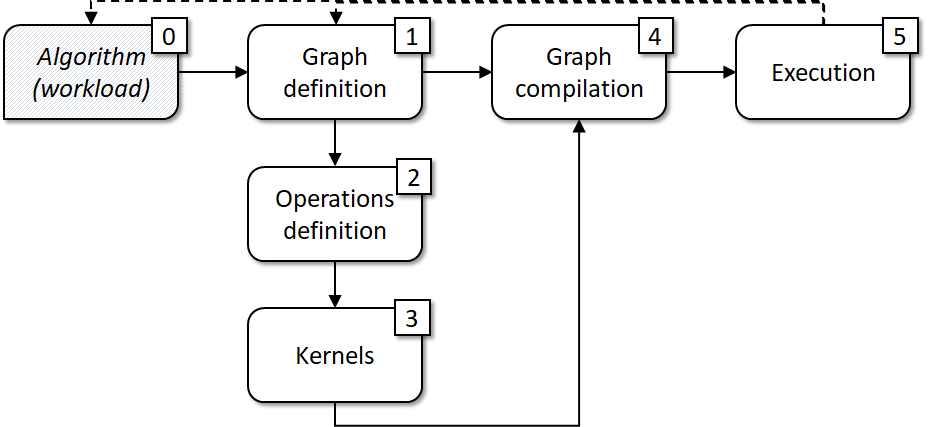
Basically, it is a derivative from the programming model illustrated in the previous chapter. You start with an algorithm or a data flow in mind (0), mapping it to a graph model (1), then identifying what operations you need (2) to construct this graph. These operations may already exist in G-API or be missing, in the latter case we implement the missing ones as kernels (3). Then decide which execution model fits our case better, pass kernels and DL networks as arguments to the compilation process (4), and finally switch to the execution (5). The process is iterative, so if you want to change anything based on the execution results, get back to steps (0) or (1) (a dashed line).