Optimize Classification Model¶
Summary¶
INT8 Calibration is a universal method for accelerating deep learning models. Calibration is a process of converting a Deep Learning model weights to a lower 8-bit precision such that it needs less computation.
In this tutorial, you will learn how to optimize your model using INT8 Calibration, examine how much quicker the model has become, and check the difference between original and optimized model accuracy.
Model |
Task Type |
Framework |
Source |
Dataset |
|---|---|---|---|---|
You can learn how to import the model and create a not annotated dataset in the DL Workbench Get Started Guide.
Optimize Model Using INT8 Calibration¶
To convert the model to INT8, go to Perform tab on the Project page and open Optimize subtab. Check INT8 and click Optimize.
Once a model has been inferred in the DL Workbench, you can convert it from FP32 to INT8. Go to the Perform tab on the Project page and open the Optimize subtab. Check INT8 and click Optimize.
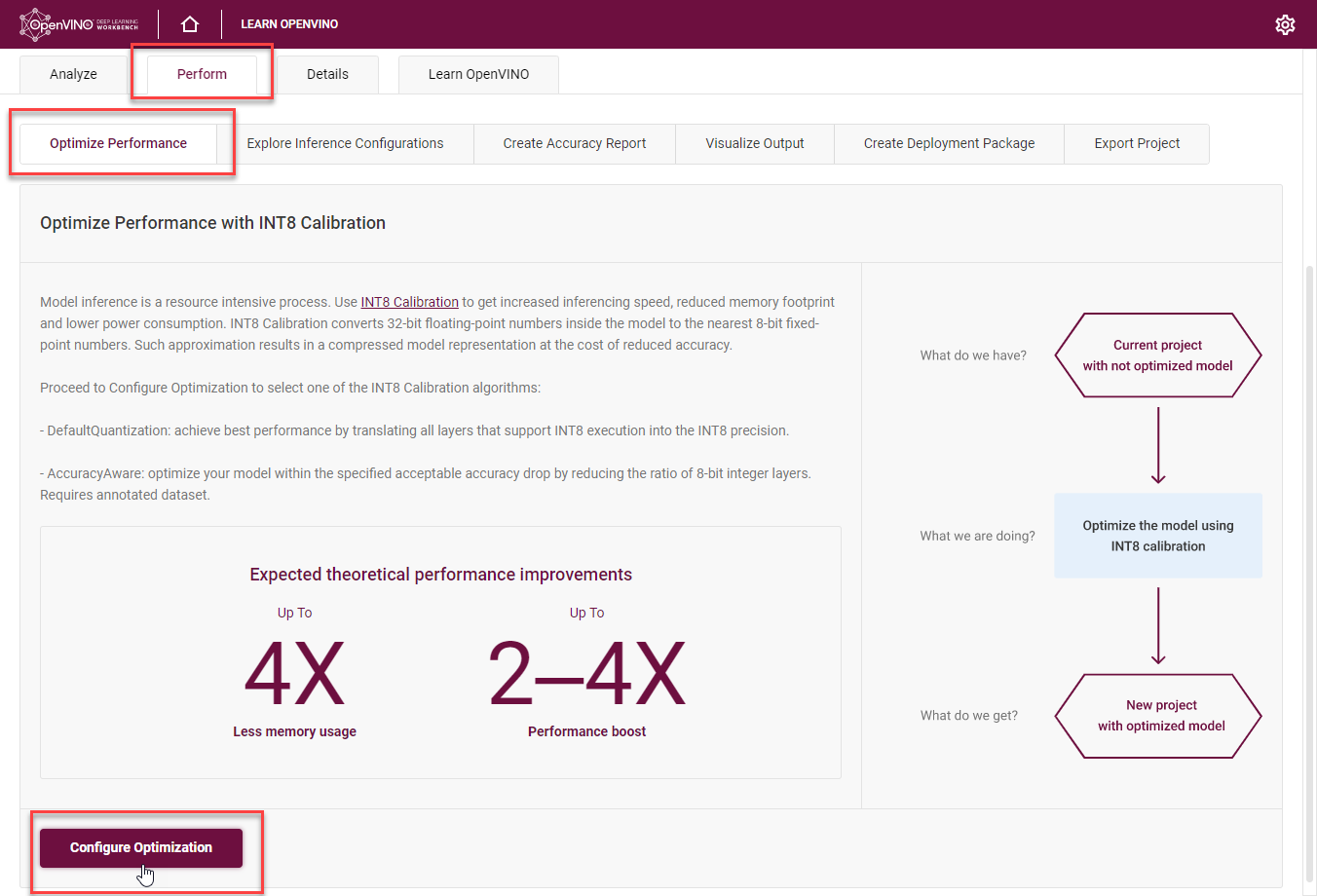
It takes you to the Optimize INT8 page. Select the imported dataset and perform INT8 Calibration with Default optimization method and Performance Preset calibration scheme first as it provides maximum performance speedup.
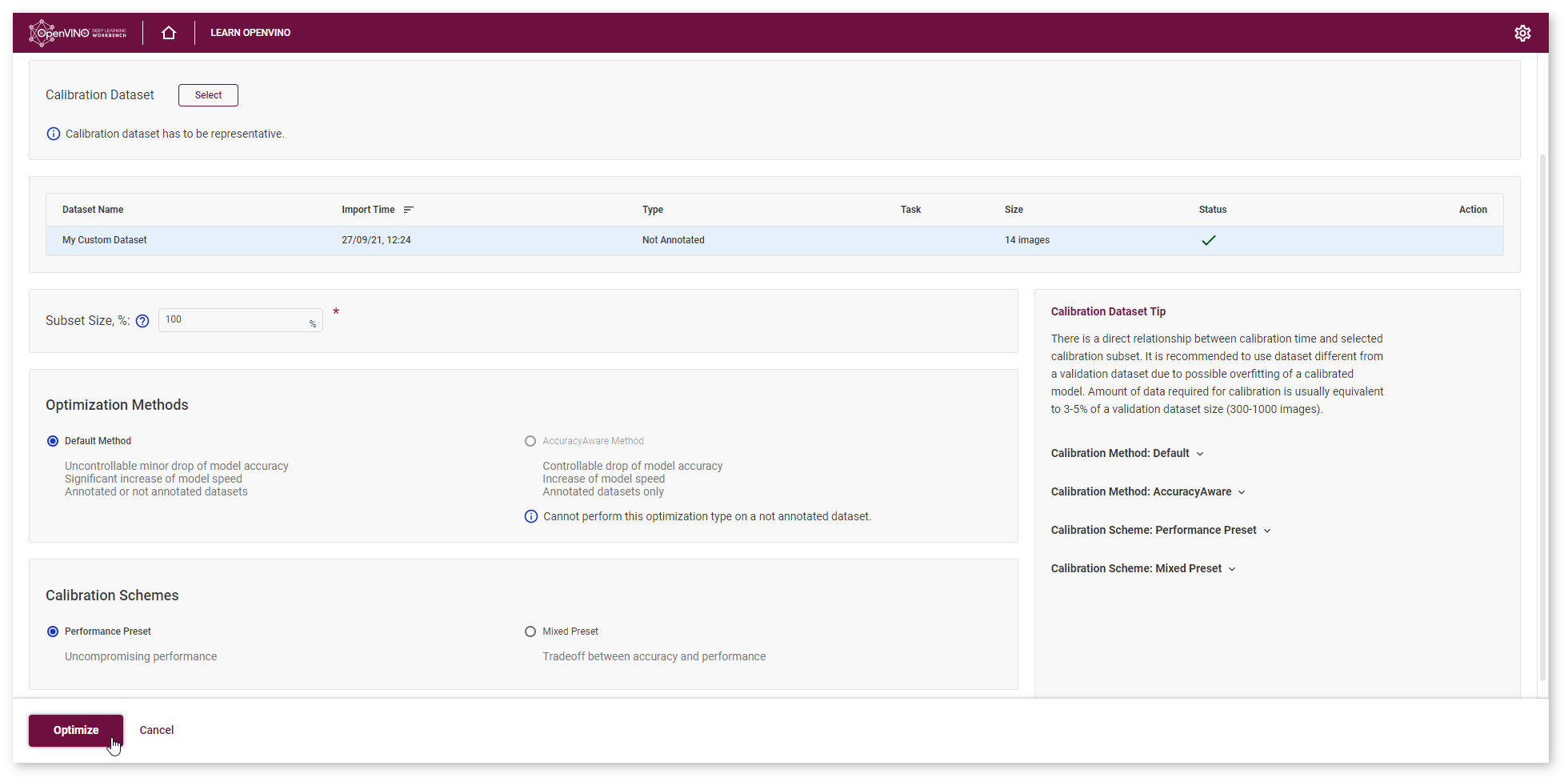
After optimization, you will be redirected to a new Project page for optimized mobilenet-v2 model.
To ensure that the optimized model performance is sufficiently accelerated and its predictions can be trusted, evaluate the key characteristics: performance and accuracy.
Compare Optimized and Parent Model Performance¶
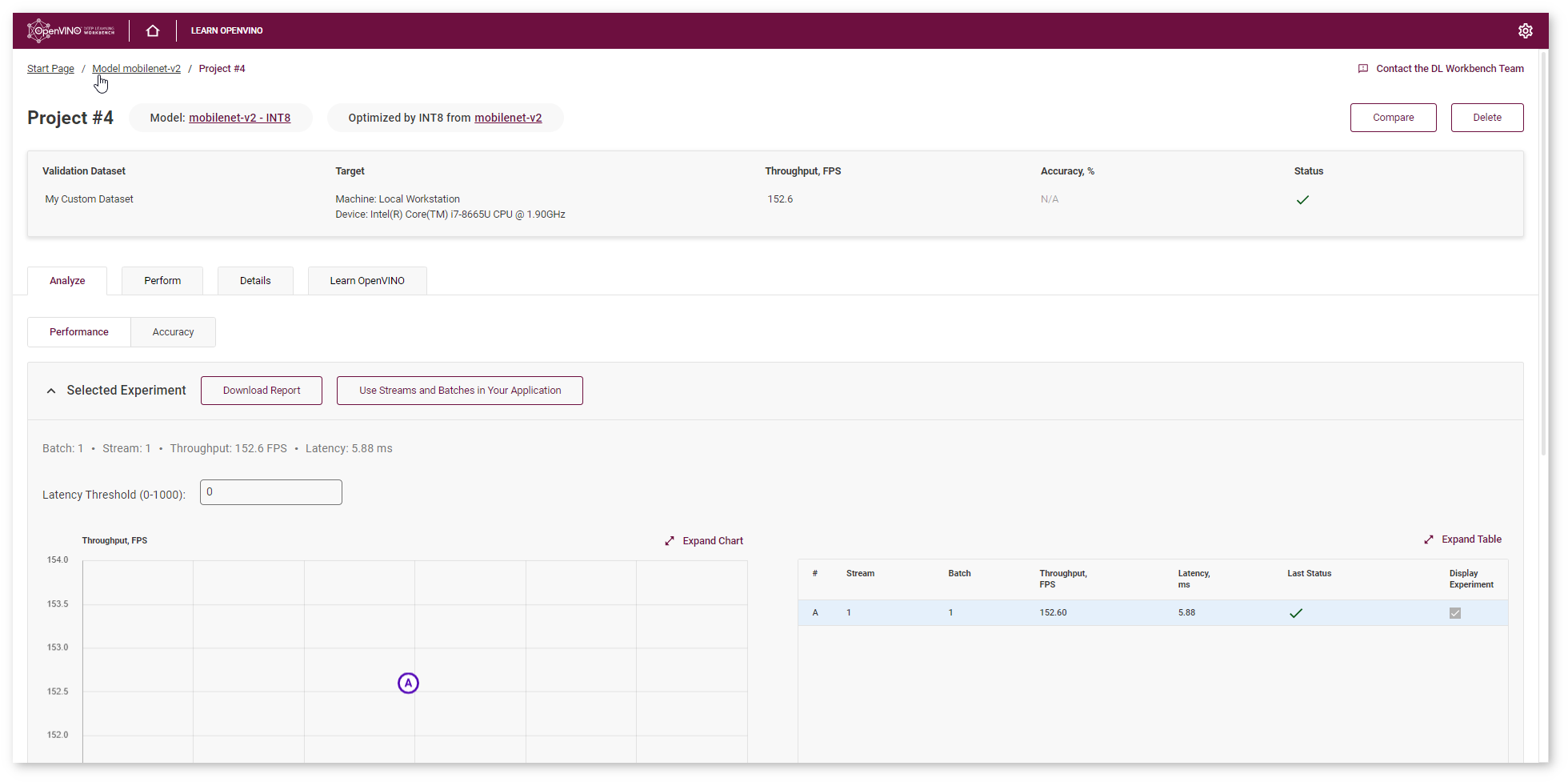
Go to the model page and check the performance of the imported and optimized models. Compare the throughput numbers and click Compare Projects. Learn more about projects comparison on the Compare Performance page.
NOTE: Throughput is the number of images processed in a given amount of time. It is measured in frames per second (FPS). Higher throughput value means better performance.
You can observe that mobilenet_v2 model has become 1.2x times faster on CPU device after optimization.
Lowering the precision of the model using quantization leads to a loss in prediction capability. Therefore you need to assess the model prediction capability to ensure that you have not lost a significant amount of accuracy.
Compare Parent and Optimized Model Predictions¶
Create Accuracy Report¶
Go to the Perform tab and select Create Accuracy Report :
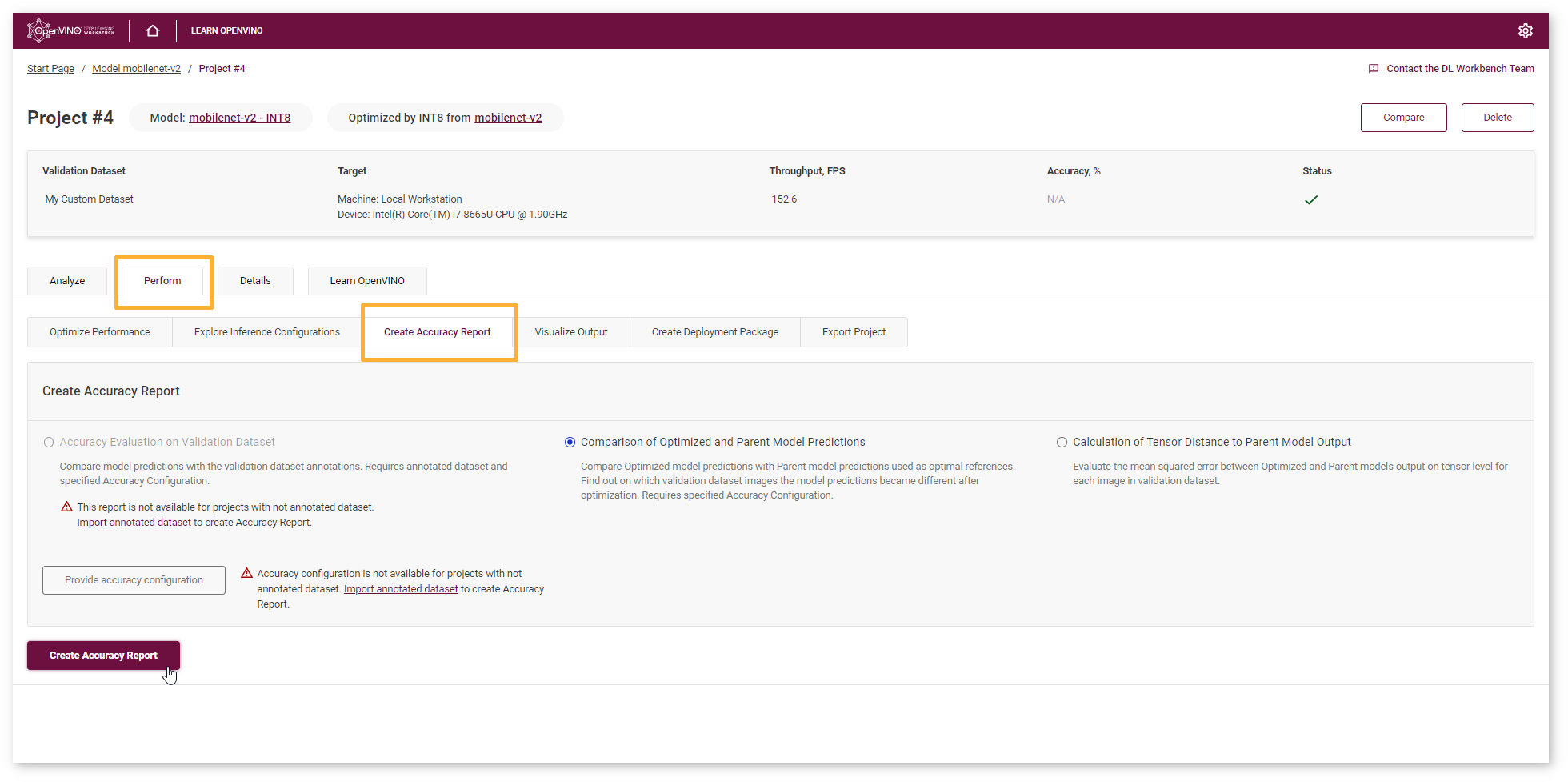
Comparison of Optimized and Parent Model Predictions Report allows you to find out on which validation dataset images the predictions of the model have become different after optimization. Let’s compare Optimized model predictions with Parent model predictions used as optimal references.
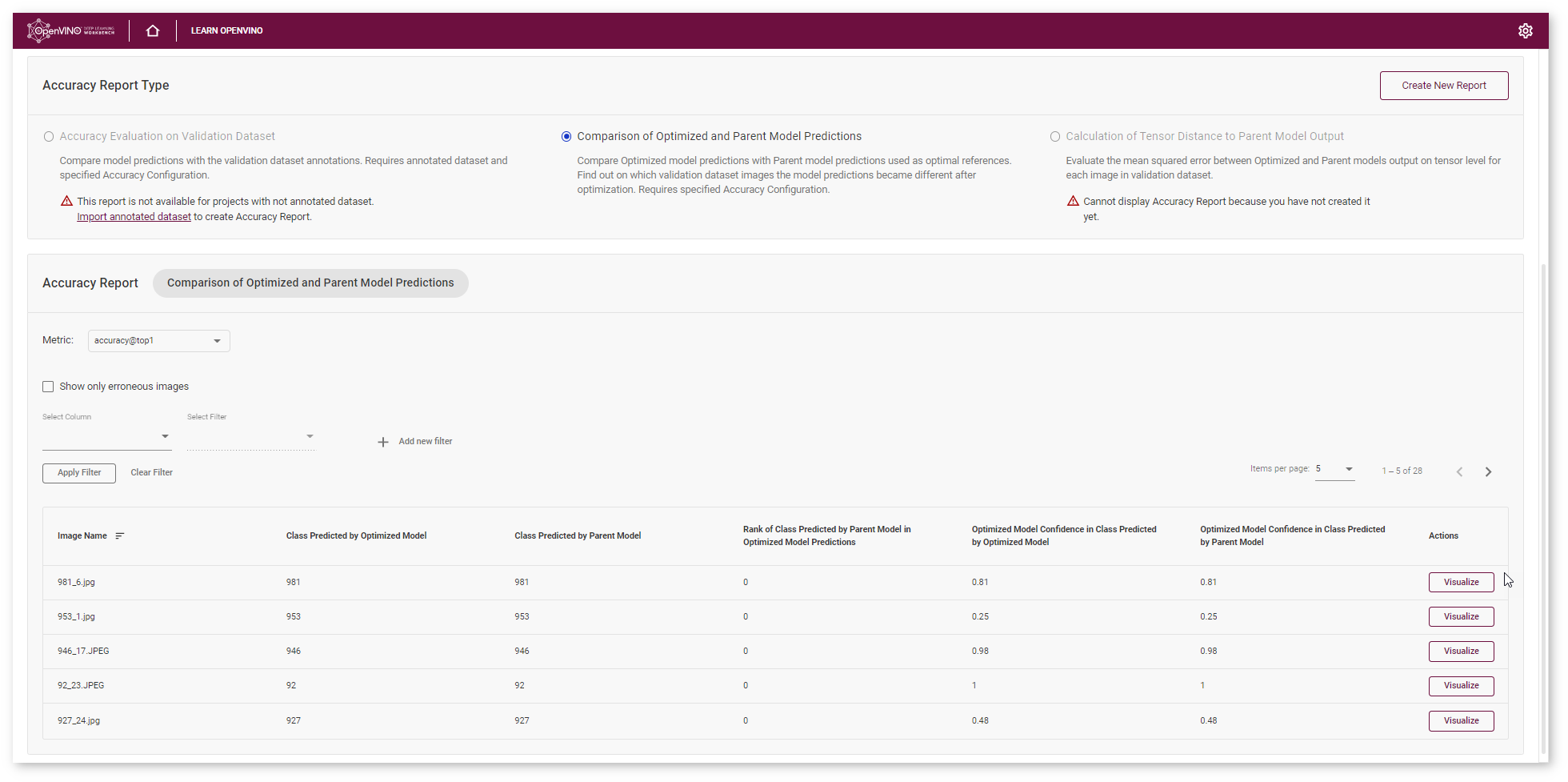
Interpret Report Results¶
Each line of the table contains a specific class that the model predicted for the object in the image - Class Predicted by Optimized Model. You can compare this class with the Class Predicted by Parent Model.
If the classes do not match, the Optimized model might be incorrect. To assess the difference between the classes, check the Rank of Class Defined in Parent Model Predictions. You can also compare optimized Model Confidence in Class Predicted by Optimized Model with Optimized Model Confidence in Class Predicted by Parent Model.
Tip
To sort the numbers from lowest to highest, click on the parameter name in the table.
Click Visualize button under the Actions column to compare the predictions and annotations for a particular image.
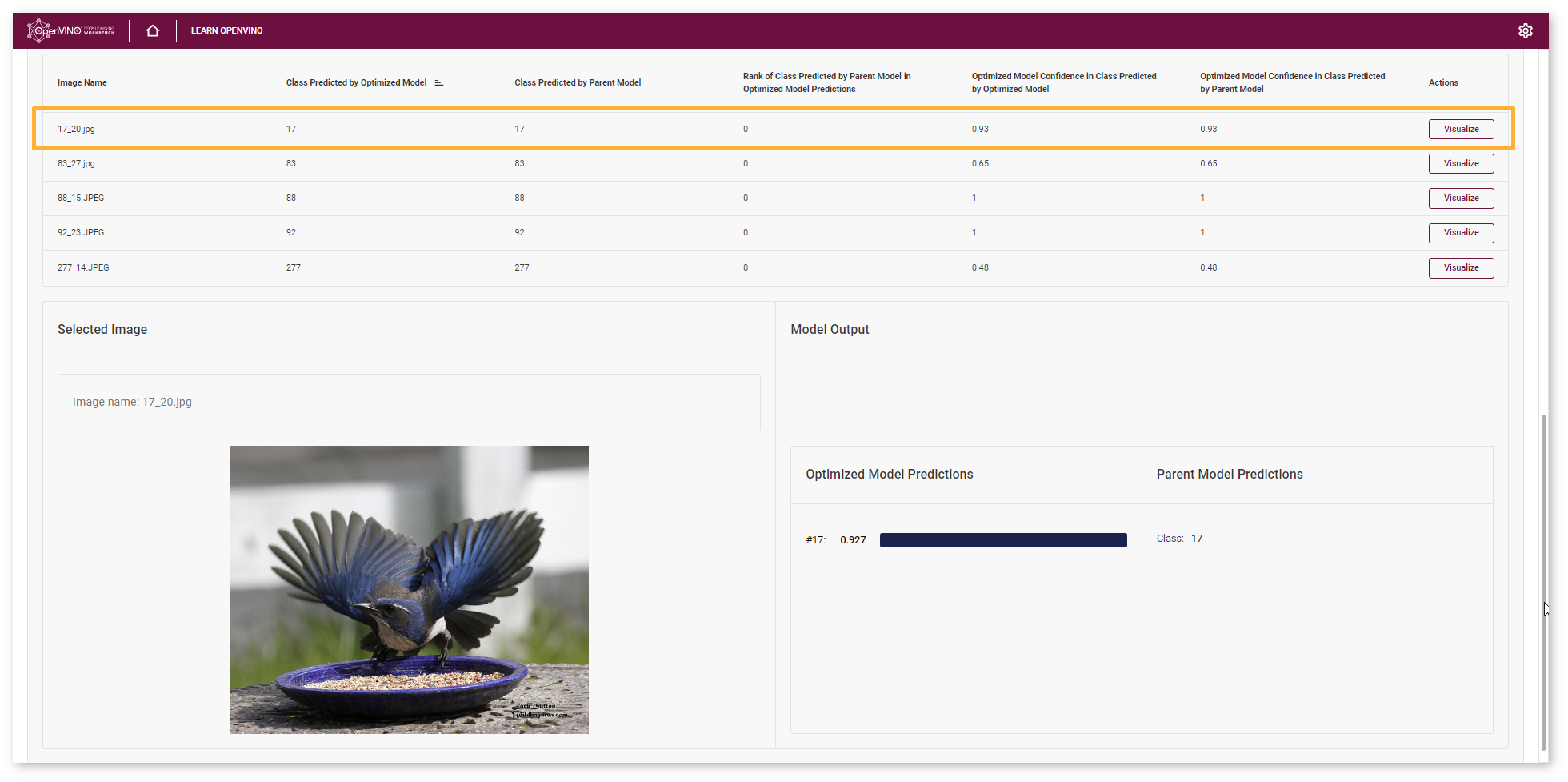
In the example image, the Optimized mobilenet-v2 model predicted the same class as the Parent model (bird) with confidence equaled 0.93.
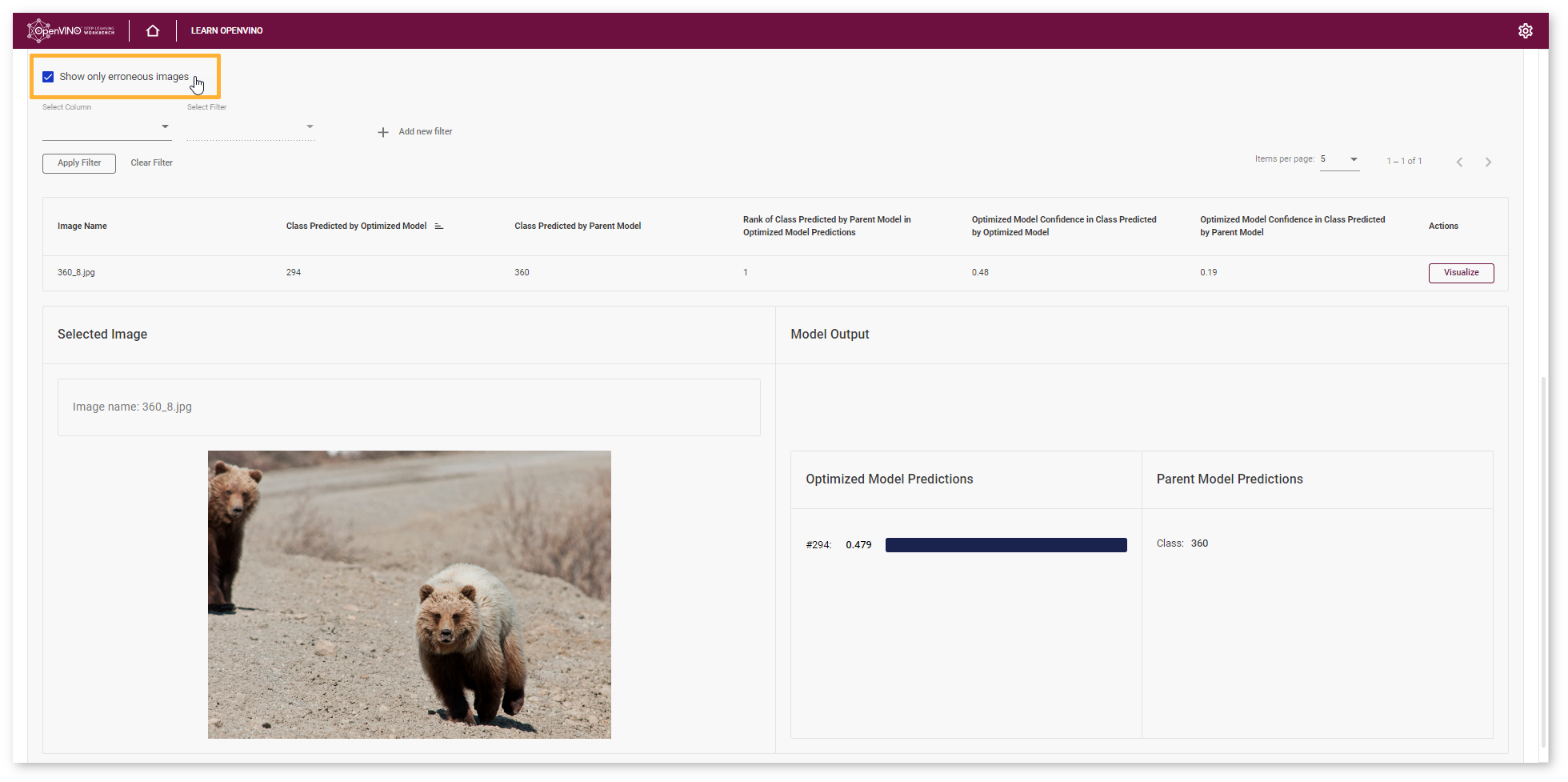
Check Show only erroneous images option to display only images where the classes predicted by the model and specified in dataset annotations do not match.
Another type of Accuracy Report available for not annotated datasets is Calculation of Tensor Distance to Parent Model Output. The report enables you to identify differences between Parent and Optimized model predictions for a wider set of use cases besides classification and object detection. Learn more in the Style Transfer model tutorial.
Next Step¶
After evaluating the accuracy, you can decide whether the difference between imported and optimized models predictions is critical or not:
If the tradeoff between accuracy and performance is too big, import an annotated dataset and use AccuracyAware optimization method, then repeat the steps from this tutorial.
If the tradeoff is acceptable, explore inference configurations to further enhance the performance. Then create a deployment package with your ready-to-deploy model.
All images were taken from ImageNet, Pascal Visual Object Classes, and Common Objects in Context datasets for demonstration purposes only.