Model Caching Overview¶
Introduction¶
As described in the Integrate OpenVINO™ with Your Application, a common application flow consists of the following steps:
Create a Core object : First step to manage available devices and read model objects
Read the Intermediate Representation : Read an Intermediate Representation file into an object of the
ov::ModelPrepare inputs and outputs : If needed, manipulate precision, memory layout, size or color format
Set configuration : Pass device-specific loading configurations to the device
Compile and Load Network to device : Use the
ov::Core::compile_model()method with a specific deviceSet input data : Specify input tensor
Execute : Carry out inference and process results
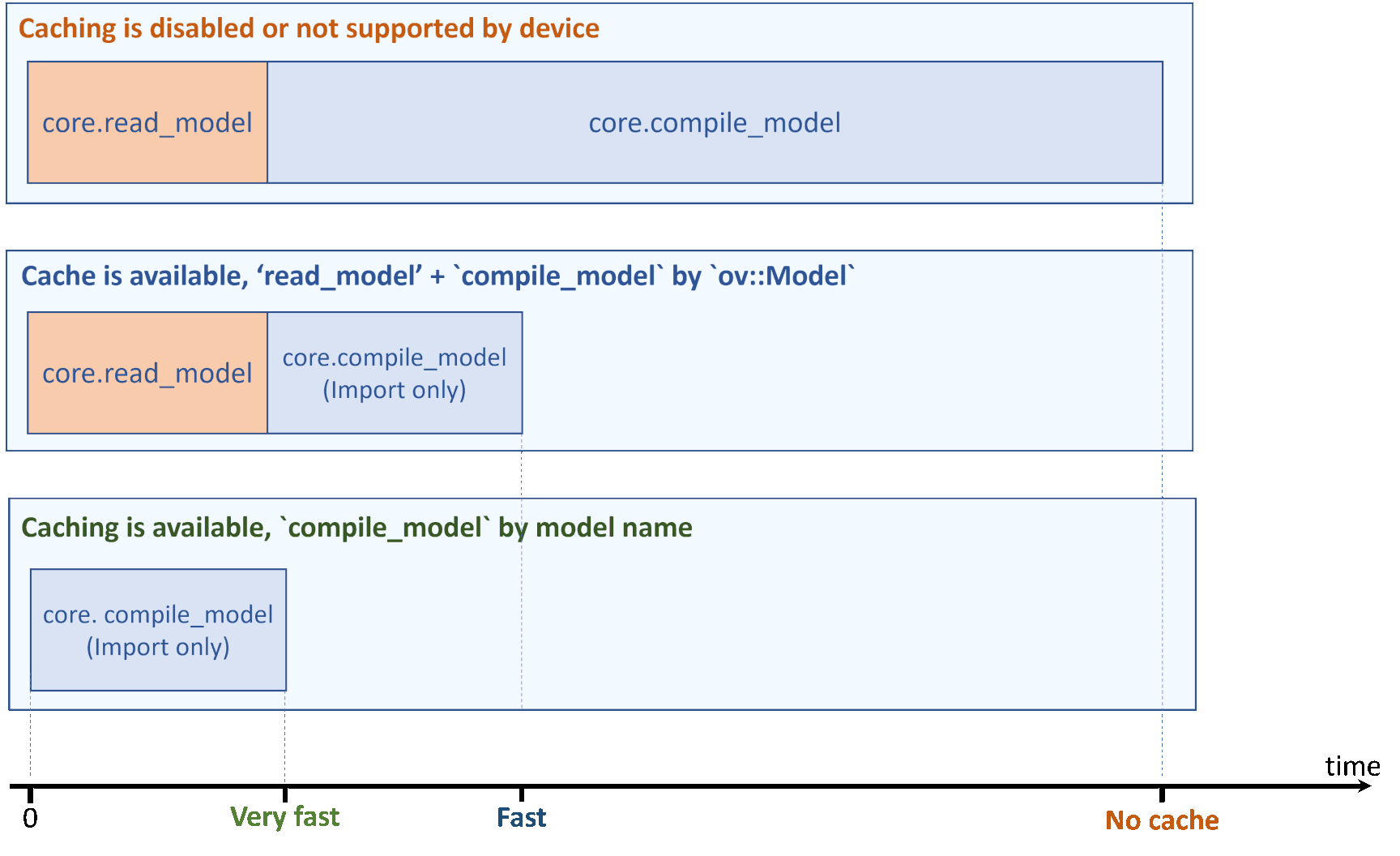
Step 5 can potentially perform several time-consuming device-specific optimizations and network compilations, and such delays can lead to a bad user experience on application startup. To avoid this, some devices offer import/export network capability, and it is possible to either use the Compile tool or enable model caching to export compiled model automatically. Reusing cached model can significantly reduce compile model time.
Set “cache_dir” config option to enable model caching¶
To enable model caching, the application must specify a folder to store cached blobs, which is done like this:
With this code, if the device specified by device_name supports import/export model capability, a cached blob is automatically created inside the /path/to/cache/dir folder. If the device does not support import/export capability, cache is not created and no error is thrown.
Depending on your device, total time for compiling model on application startup can be significantly reduced. Also note that the very first compile_model (when cache is not yet created) takes slightly longer time to “export” the compiled blob into a cache file:

Even faster: use compile_model(modelPath)¶
In some cases, applications do not need to customize inputs and outputs every time. Such application always call model = core.read_model(...), then core.compile_model(model, ..) and it can be further optimized. For these cases, there is a more convenient API to compile the model in a single call, skipping the read step:
With model caching enabled, total load time is even smaller, if read_model is optimized as well.
Advanced Examples¶
Not every device supports network import/export capability. For those that don’t, enabling caching has no effect. To check in advance if a particular device supports model caching, your application can use the following code:
Note
The GPU plugin does not have the EXPORT_IMPORT capability, and does not support model caching yet. However, the GPU plugin supports caching kernels (see the GPU plugin documentation). Kernel caching for the GPU plugin can be accessed the same way as model caching: by setting the CACHE_DIR configuration key to a folder where the cache should be stored.