Automatic device selection¶
The Automatic Device Selection mode, or AUTO for short, uses a “virtual” or a “proxy” device, which does not bind to a specific type of hardware, but rather selects the processing unit for inference automatically. It detects available devices, picks the one best-suited for the task, and configures its optimization settings. This way, you can write the application once and deploy it anywhere.
The selection also depends on your performance requirements, defined by the “hints” configuration API, as well as device priority list limitations, if you choose to exclude some hardware from the process.
The logic behind the choice is as follows:
Check what supported devices are available.
Check precisions of the input model (for detailed information on precisions read more on the
ov::device::capabilities)Select the highest-priority device capable of supporting the given model, as listed in the table below.
If model’s precision is FP32 but there is no device capable of supporting it, offload the model to a device supporting FP16.
+——- +————————————————— +———————————- + | Device || Supported || Supported | | Priority || Device || model precision | +==========+======================================================+=====================================+ | 1 || dGPU | FP32, FP16, INT8, BIN | | || (e.g. Intel® Iris® Xe MAX) | | +——- +————————————————— +———————————- + | 2 || iGPU | FP32, FP16, BIN | | || (e.g. Intel® UHD Graphics 620 (iGPU)) | | +——- +————————————————— +———————————- + | 3 || Intel® Movidius™ Myriad™ X VPU | FP16 | | || (e.g. Intel® Neural Compute Stick 2 (Intel® NCS2)) | | +——- +————————————————— +———————————- + | 4 || Intel® CPU | FP32, FP16, INT8, BIN | | || (e.g. Intel® Core™ i7-1165G7) | | +——- +————————————————— +———————————- +
To put it simply, when loading the model to the first device on the list fails, AUTO will try to load it to the next device in line, until one of them succeeds. What is important, AUTO always starts inference with the CPU, as it provides very low latency and can start inference with no additional delays. While the CPU is performing inference, AUTO continues to load the model to the device best suited for the purpose and transfers the task to it when ready. This way, the devices which are much slower in compiling models, GPU being the best example, do not impede inference at its initial stages. For example, if you use a CPU and a GPU, first-inference latency of AUTO will be better than GPU itself.
Note that if you choose to exclude the CPU from the priority list, it will also be unable to support the initial model compilation stage.
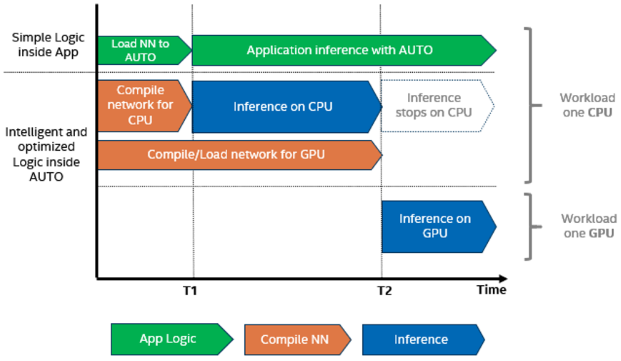
This mechanism can be easily observed in our Benchmark Application sample (see here), showing how the first-inference latency (the time it takes to compile the model and perform the first inference) is reduced when using AUTO. For example:
./benchmark_app -m ../public/alexnet/FP32/alexnet.xml -d GPU -niter 128
./benchmark_app -m ../public/alexnet/FP32/alexnet.xml -d AUTO -niter 128
Note
The longer the process runs, the closer realtime performance will be to that of the best-suited device.
Using the Auto-Device Plugin¶
Following the OpenVINO™ naming convention, the Automatic Device Selection mode is assigned the label of “AUTO.” It may be defined with no additional parameters, resulting in defaults being used, or configured further with the following setup options:
Property |
Property values |
Description |
|---|---|---|
<device candidate list> |
AUTO: <device names>
comma-separated, no spaces
|
Lists the devices available for selection.
The device sequence will be taken as priority
from high to low.
If not specified, “AUTO” will be used as default
and all devices will be included.
|
ov::device:priorities |
device names
comma-separated, no spaces
|
Specifies the devices for Auto-Device plugin to select.
The device sequence will be taken as priority
from high to low.
This configuration is optional.
|
ov::hint::performance_mode |
ov::hint::PerformanceMode::LATENCY
ov::hint::PerformanceMode::THROUGHPUT
|
Specifies the performance mode preferred
by the application.
|
ov::hint::model_priority |
ov::hint::Priority::HIGH
ov::hint::Priority::MEDIUM
ov::hint::Priority::LOW
|
Indicates the priority for a model.
Importantly!
This property is still not fully supported
|
Inference with AUTO is configured similarly to when device plugins are used: you compile the model on the plugin with configuration and execute inference.
Device candidate list¶
The device candidate list allows users to customize the priority and limit the choice of devices available to the AUTO plugin. If not specified, the plugin assumes all the devices present in the system can be used. Note, that OpenVINO™ Runtime lets you use “GPU” as an alias for “GPU.0” in function calls. The following commands are accepted by the API:
To check what devices are present in the system, you can use Device API. For information on how to do it, check Query device properties and configuration
For C++
ov::runtime::Core::get_available_devices() (see Hello Query Device C++ Sample)
For Python
openvino.runtime.Core.available_devices (see Hello Query Device Python Sample)
Performance Hints¶
The ov::hint::performance_mode property enables you to specify a performance mode for the plugin to be more efficient for particular use cases.
ov::hint::PerformanceMode::THROUGHPUT¶
This mode prioritizes high throughput, balancing between latency and power. It is best suited for tasks involving multiple jobs, like inference of video feeds or large numbers of images.
ov::hint::PerformanceMode::LATENCY¶
This mode prioritizes low latency, providing short response time for each inference job. It performs best for tasks where inference is required for a single input image, like a medical analysis of an ultrasound scan image. It also fits the tasks of real-time or nearly real-time applications, such as an industrial robot’s response to actions in its environment or obstacle avoidance for autonomous vehicles. Note that currently the ov::hint property is supported by CPU and GPU devices only.
To enable performance hints for your application, use the following code:
The property enables you to control the priorities of models in the Auto-Device plugin. A high-priority model will be loaded to a supported high-priority device. A lower-priority model will not be loaded to a device that is occupied by a higher-priority model.
Configuring Individual Devices and Creating the Auto-Device plugin on Top¶
Although the methods described above are currently the preferred way to execute inference with AUTO, the following steps can be also used as an alternative. It is currently available as a legacy feature and used if the device candidate list includes Myriad devices, uncapable of utilizing the Performance Hints option.
Using AUTO with OpenVINO™ Samples and the Benchmark App¶
To see how the Auto-Device plugin is used in practice and test its performance, take a look at OpenVINO™ samples. All samples supporting the “-d” command-line option (which stands for “device”) will accept the plugin out-of-the-box. The Benchmark Application will be a perfect place to start – it presents the optimal performance of the plugin without the need for additional settings, like the number of requests or CPU threads. To evaluate the AUTO performance, you can use the following commands:
For unlimited device choice:
benchmark_app –d AUTO –m <model> -i <input> -niter 1000
For limited device choice:
benchmark_app –d AUTO:CPU,GPU,MYRIAD –m <model> -i <input> -niter 1000
For more information, refer to the C++ or Python version instructions.
Note
The default CPU stream is 1 if using “-d AUTO”.
You can use the FP16 IR to work with auto-device.
No demos are yet fully optimized for AUTO, by means of selecting the most suitable device, using the GPU streams/throttling, and so on.